

TOXICOLOGY DATABASE
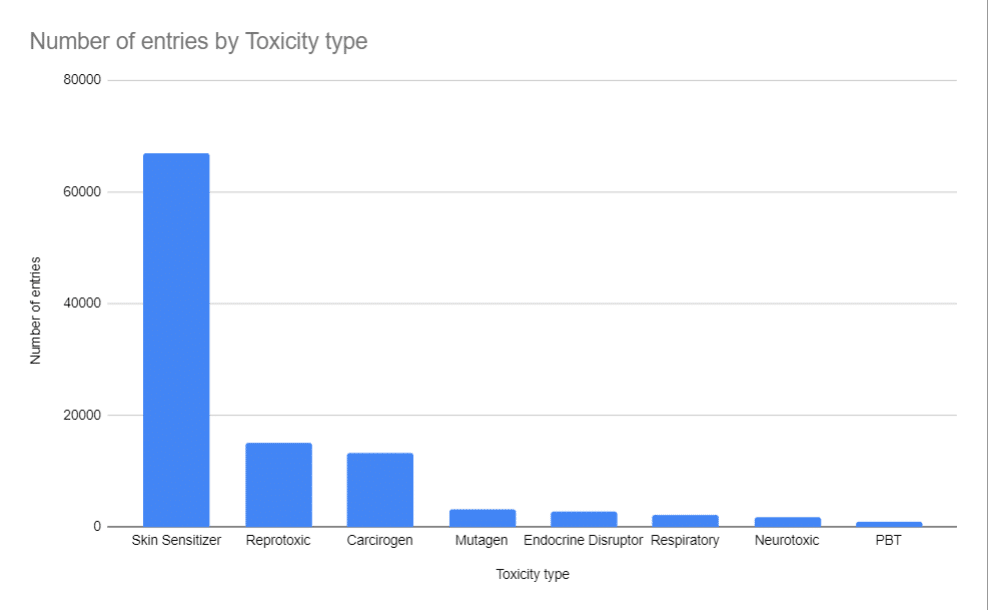
Firstly, we have a proprietary collection of 78,000 toxic compounds which are subdivided into 8 toxicity datasets as depicted below.
STATISTICAL MODELS
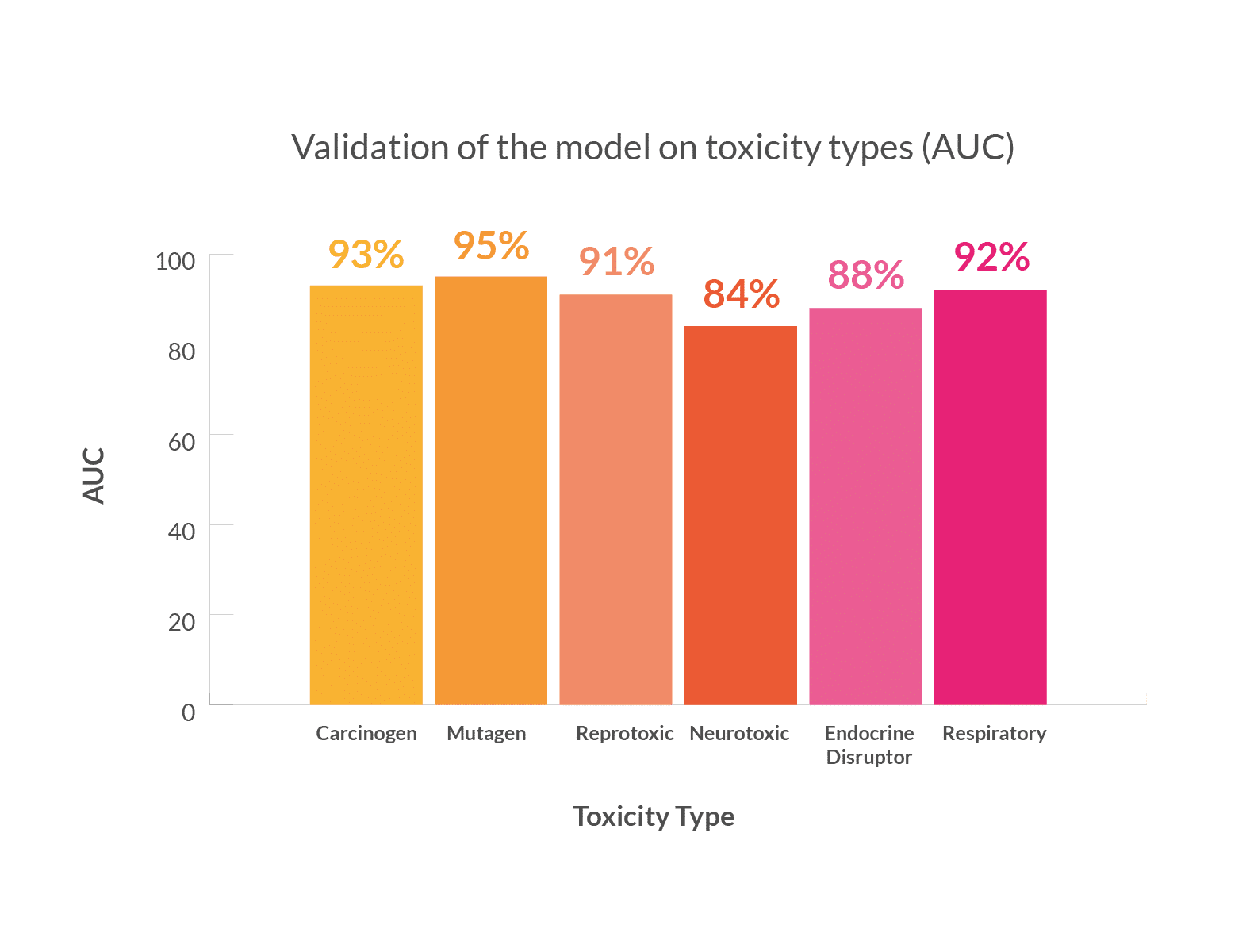
For each toxicity dataset, we built a dedicated statistical QSAR model using a machine learning approach.
For each model, we provide appropriate measures of robustness and predictivity as exemplified with the graph below.
For each molecule to be processed, we first check if the structure is comprised in the domain of applicability of the models.
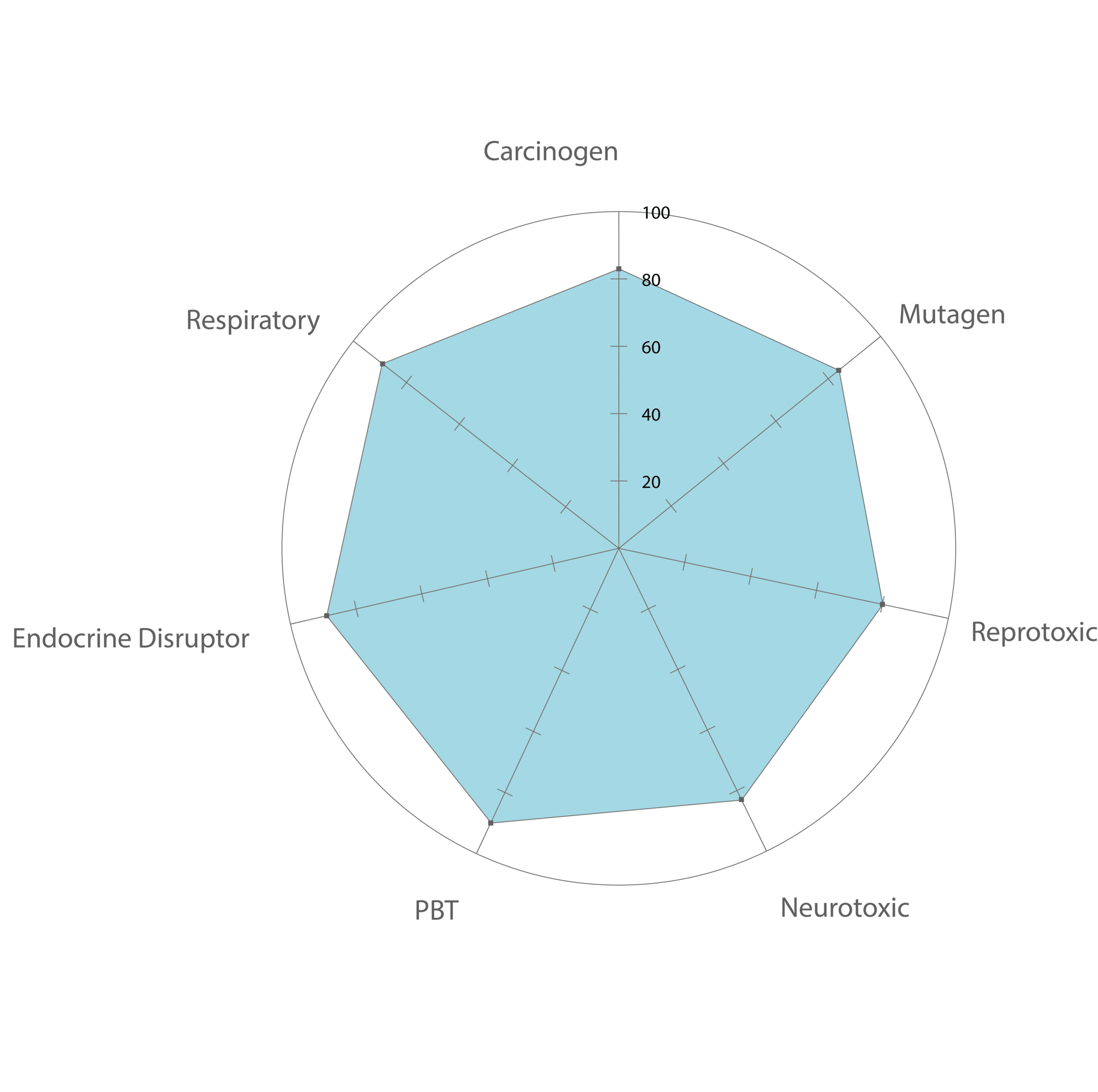
As result, we predict a full toxicity profile of a chemical telling if the compound is classified as toxic or non-toxic with a statistical confidence with regard to the 7 toxicity endpoints.
Our toxicity models are able to process molecules in a batch mode.
EXAMPLE OF USE CASE
Our toxicity models have already been used with clients from the chemistry and cosmetics industries.